- Published on
AI vs If/else
- Author

- Nom
- Ngoc Duong van
Hôm nay ngồi cafe, mấy anh em đùa là: nhiều hệ thống AI bây giờ toàn là if/else không à, AI cái nỗi gì! Vui là thế, nhưng cách nói này cũng không phải là vô lý đâu. Vậy nó có lý ở đâu, vô lý ở đâu?
1. Có lý ở chỗ: thực ra có thể coi
AI = hàng tỷ phép tính if-else nối vào nhau theo một cấu trúc phức tạp
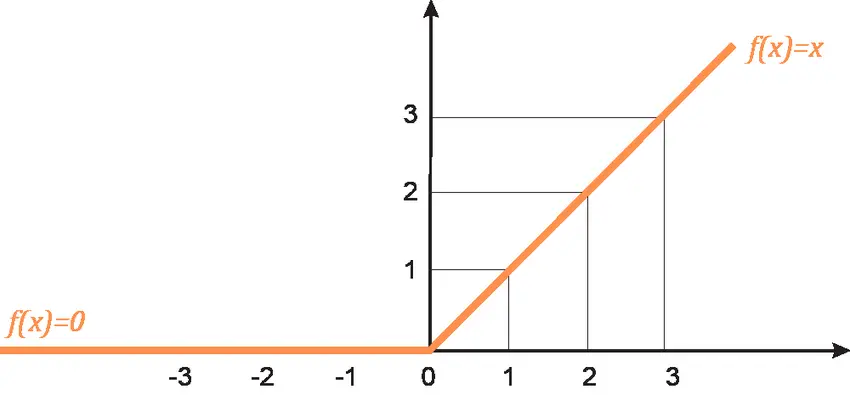
Chứng minh: Nếu nhìn vào ReLU function (hàm số quan trọng tại các nốt mạng, nó là lý do mà neuron network có khả năng học được các quy luật phi tuyến tính), ta thấy nó có thể được viết thành:
if (x > 0) {
y = x
} else {
y = 0
}
2. Vô lý ở chỗ:
Một giải thuật if-else được viết ra bởi lập trình viên, giỏi lắm thì viết được 10 đến 20 tầng logic là chết mệt rồi, bảo viết 1 tỷ cái thì chắc chắn là bất khả thi!
// Giải thuật viết bằng các điều kiện lồng nhau
if () {
if () {} else {}
...
} else {
if () {} else {}
...
}
Hai giải thuật này giống nhau về nguyên lý, khác nhau về quy mô. Nếu không hiểu rõ thì sẽ thấy tất cả nó loạn cào cào, ông nào cũng viết if-else rồi gọi đó là AI hết.
Tới đây ta thấy rằng: nếu quy mô tính toán của AI lớn như vậy, thì: phải chăng lập trình viên quá kém hiệu quả?
Câu trả lời là: không hẳn.
Điểm mạnh và yếu của AI
Mặc dù AI mạnh là thế, nhưng để đạt được điều đó, nó phải đánh đổi 2 thứ quan trọng sau:
1- Để giải bài toán bằng AI, ta cần dữ liệu, chất lượng của dữ liệu ảnh hưởng trực tiếp đến chất lượng lời giải. Điều này là hệ quả của cách tiếp cận lời giải bằng AI: cách tiếp cận ngược.
Việc tìm lời giải bằng AI giống như Conan tìm hung thủ gây án vậy: dữ liệu là bằng chứng, model AI là quy trình gây án, quá trình suy luận tìm hung thủ là các thuật toán tối ưu, nếu bằng chứng ít, hoặc không chính xác, kết luận đưa ra sẽ không chính xác. Khi bằng chứng ít, ta có rất nhiều giải thuyết gây án - tức là model AI của ta khó tối ưu. Mỗi khi có thêm bằng chứng, số lượng giả thuyết gây án hẹp lại, ta lại càng tự tin với kết luận hơn, tức là model AI càng chính xác hơn.
Điểm yếu của phương pháp này là dữ liệu không chỉ ảnh hưởng đến lời giải mà nó còn chính là một phần của lời giải. Suy cho cùng, dù Conan có tự tin đến mấy, nếu hung thủ quyết không nhận tội, thì vẫn có khả năng hắn bị oan.
2- Vì mô hình toán trong lời giải bằng phương pháp AI là rất phức tạp (hàng tỷ tham số) nên sẽ khó có cách nào kiểm soát được toàn bộ đầu ra của lời giải.
Với lượng tham số rất lớn, việc chứng minh chính xác bằng toán học về tính an toàn của các kết quả đầu ra là một bài toàn nan giải. Tức là không thể chứng minh được rằng: không tồn tại một điểm kỳ dị nào đó trong không gian biến đầu vào khiến đầu ra là một kết quả không mong muốn. Các kết quả chỉ được kiểm soát trong giới hạn các điểm dữ liệu huấn luyện và thử nghiệm, ngoài các khu vực này, mô hình có thể mất kiểm soát.
Ví dụ đầu ra của mô hình AI có một tín hiệu kích hoạt bom hạt nhân chẳng hạn, ta mong muốn điều này chắc chắn chỉ xảy ra với các điều kiện chính xác. Tuy nhiên ta lại không chắc được rằng liệu có một điểm kỳ dị đầu vào nào đó khiến tín hiệu kích hoạt xuất hiện không? Điều này rất nguy hiểm!
Vì vậy, để làm những việc quan trọng, dù mô hình có phức tạp tới đâu, vẫn cần các kỹ sư thực hiện từng chút một để đảm bảo kiếm soát được quá trình.
Câu hỏi đặt ra ở đây là nếu không kiểm soát đầu vào và mô hình, thì ta kiểm soát đầu ra là được mà, như ví dụ trên, chặn đầu ra là luôn không kích hoạt bom hoặc khi kích hoạt bom thì báo động là được?
Cách nghĩ này đối với các bài toán AI kiểu cũ thì ổn đấy, nhưng với sự ra đời của AI tạo sinh (GenAI) thì điều này phức tạp hơn. Sau đây ta sẽ thấy rằng, GenAI là cực kỳ nguy hiểm, vì cả đầu vào và đầu ra đều có thể mất kiểm soát!
Generative AI
Để hiểu GenAI, ta cần biết động lực chính để chúng ta nghiên cứu và phát triển nó, tức là vì sao GenAI lại ra đời? Và động lực đầu tiên đến từ nhận định:
1- Con người không nên là giới hạn trong việc phát triển năng lực của AI
Xét ví dụ bài toán nhận dạng ảnh chó vs mèo. Với bài toán này, phương pháp tiếp cận không dùng GenAI là:
Bước 1: Chụp thật nhiều ảnh chó và mèo.
Bước 2: Gán nhãn bằng tay các hình ảnh này -> dùng tập dữ liệu này để huấn luyện.
Nhìn vào quá trình trên, rõ ràng là AI đang học hỏi từ con người, điều này hoàn toàn không có gì sai cả, nhưng câu hỏi mở ra ở đây là: nếu AI học từ con người, vậy thì con người học hỏi từ đâu? Nếu con người không học từ đâu cả, vậy tại sao AI không thể làm vậy?
Phát triển ý tưởng này và áp dụng vào bài toán trên, ta bỏ đi quá trình gán nhãn, đưa vào mô hình AI một tập dữ liệu gồm tất cả các loài vật không gán nhãn, và để AI tự quyết định giống như con người, xem trong tập có bao nhiêu loài vật thì tối ưu và tự gán nhãn cho chúng (học không giám sát).
Để hiểu rõ hơn ý này, xét bài toán phân loại chó và mèo: cho 1000 hình ảnh bao gồm ảnh chó và mèo, tạm quên đi toàn bộ tri thức về loài chó và loài mèo, như cách một đứa trẻ lần đầu tiên nhìn thấy 1000 bức ảnh này, liệu lũ trẻ có thể đưa ra kết luận là trong này có 2 loài vật không?
Câu trả lời tất nhiên là có hoặc không, nhưng vấn đề là khi nào là có? -> là khi định nghĩa của chúng ta và lũ trẻ về loài vật là giống nhau -> điều này lại đúng khi mục đích của ta và lũ trẻ khi định nghĩa loài vật là giống nhau. Điều này lại dẫn đến mục đích định nghĩa các loài vật để làm gì?
Việc tiếp tục đào sâu sẽ dẫn đến các nguyên lý cơ bản của triết học - cách mà con người bắt đầu tư duy (ví dụ như sự thống nhất, sự đối lập, sự tương phản...). Và điều này dẫn đến đột phá của trong phát triển AI: thay vì dạy AI kết quả của sự tư duy (đâu là chó, đâu là mèo) thì chúng ta dạy AI cách tư duy (sự đối lập, sự phân biệt), từ những nguyên lý cơ bản này AI sẽ dùng nó để phân tích thế giới như cách con người đã làm trong suốt hàng nghìn năm qua.
Và từ thực nghiệm, trong các nguyên lý tư duy, người ta thấy rằng xác suất là một nguyên lý tuyệt vời cả về mặt toán học và trực giác để mô hình hoá cách con người học hỏi vì: xác suất cho ta một thước đo định lượng về “sự chắc chắn”, và sự chắc chắn, là tiền đề cho những hiểu biết của chúng ta về thế giới (?).
Mặc dù nhận định thứ nhất là rất tốt, nhưng vẫn là chưa đủ để thúc đẩy làn sóng GenAI. Nhận định số 2 sau đây, tưởng như rất phổ quát và xưa cũ trong giới khoa học, theo mình, lại là động lực quan trọng thúc đẩy phát triển GenAI.
2- Việc tìm hiểu quy luật vận động đằng sau các hiện tượng sẽ giúp ta hiểu các hiện tượng tốt hơn là tìm hiểu các biểu hiện bên ngoài của chúng, và các quy luật này thường đơn giản + mang tính phổ quát cao hơn.
Khi thấy quả táo rơi, Newton đi tìm hiểu nguyên nhân đằng sau nó - lực hấp dẫn- thay vì hướng, vận tốc và thời gian rơi của quá táo. Và quy luật này có thể áp dụng cho các vật từ nhỏ như quả táo tới lớn như các hành tinh. Sau đó, khi tìm quy luật chuyển động của các hành tinh, thay vì trực tiếp tìm hiểu quy luật (mà ở đó có rất nhiều sự tương tác qua lại phức tạp giữa nhiều hành tinh), ta có thể sử dụng hiểu biết này để giải. Ý niệm chính ở đây là: nhiều quy luật nhỏ đơn giản kết hợp lại sẽ nhanh chóng khiến bài toán trở nên cực kỳ phức tạp.
Việc tìm hiểu các quy luật đằng sau, như hiểu các định luật, sẽ giúp việc vận dụng và sáng tạo ra những điều không tồn tại trong tự nhiên (như chế bom hạt nhân!).
Đối chiếu với bài toán tìm hung thủ của Conan, ta có thể hiểu ý tưởng này là tập trung vào “động cơ gây án” thay vì chỉ suy đoán từ bằng chứng, từ đây ta có thể đoán được hung thủ tốt hơn vì động cơ thì không nhiều và đơn giản hơn quá trình. Việc nắm động cơ gây án khiến ta nhìn nhận quá trình gây án có hệ thống và logic hơn.
Quay lại bài toán phân loại chó và mèo, dưới góc nhìn của ý tưởng này, việc khám phá ra quy luật hình thành chó và mèo sẽ giúp ích nhiều hơn là trực tiếp giải bài toán phân loại.
Xét quá trình hình thành 1 bức ảnh loài mèo: ta bắt đầu từ ADN của loài mèo, từ ADN này sẽ hình thành, phát triển các cá thể mèo khác nhau. Các cá thể này lại được thu hình bằng các thiết bị quang học trong máy ảnh, sau đó được số hoá thành các tập dữ liệu trong bộ nhớ máy tính -> giả dụ là có tồn tại quy luật đằng sau quá trình này.
Ở một tương lai tốt đẹp, ta phân tích ADN và phát hiện ra quy luật xác định các loài phụ thuộc vào 2 biến và (nằm trong ADN) như sau:
x+y = 10 -> mèo
x+y = 20 -> chó
Bằng quy luật này, ta có thể tuỳ ý thay đổi và để tạo ra các cá thể chó và mèo mới, đồng thời bài toán phân loại cũng có dễ dàng giải được một cách hiệu quả bằng cách: tìm và từ ảnh đầu vào, sau đó tính tổng để xác định xem ảnh đầu vào là chó hay mèo.
Quá trình thay đổi sao cho để tạo ra một cá thể mèo bất kỳ gọi là tạo sinh hay “generative”. Quá trình tìm từ ảnh đầu vào là mã hoá (encoding). Quá trình từ tạo ra ảnh là giải mã (decoding). Và thực tế chỉ ra rằng, các quy luật đằng sau “sinh ra” dữ liệu thường đơn giản (hay là nằm trong các không gian có chiều thấp) hơn chính bản thân các dữ liệu đó.
Từ đây ta thấy mục tiêu của GenAI là tạo sinh các đầu ra từ “quy luật”, tức là có khả năng tạo ra các biến thể không tồn tại trong tập dữ liệu huấn luyện! Nếu tìm cách kiểm soát đầu ra, thì phải chăng sẽ khiến năng lực “tạo sinh” bị hạn chế? Điều này mâu thuẫn với mục đích tạo ra chúng!
Vấn đề không đơn giản kết thúc ở đây, sau này đầu ra bất định còn bị nâng lên một tầm cao mới với kiến trúc của LLM và diffusion, vì ... (to be continue...)
Lưu ý: GenAI được thúc đẩy chủ yếu bởi 2 nhận định trên nhưng chỉ phát triển mạnh khi Attention ra đời, để hiều các vấn đề này cần khá nhiều công cụ toán học và công nghiệ thông tin nâng cao, nên sẽ không được bàn ở đây.